FPT.AI: Hành trình chinh phục SHINRA2020-ML
Vượt qua nhiều đối thủ nặng kí đến từ khắp nơi trên thế giới, mô hình ngôn ngữ mới của FPT.AI đã giành giải nhất của cuộc thi SHINRA2020-ML với kết quả chung cuộc: Rank #1 của 25 trong số 30 ngôn ngữ; trong đó có cả những ngôn ngữ được đánh giá là khó như tiếng Hàn, tiếng Trung, tiếng Hindu.
SHINRA2020-ML là cuộc thi do Viện Nghiên cứu Khoa học Cơ bản RIKEN và Đại học Tổng hợp Tohoku – Nhật Bản tổ chức. SHINRA2020-ML là hoạt động chính trong khuôn khổ Hội nghị NTCIR lần thứ 15 – sự kiện khoa học thường niên uy tín của Nhật Bản, thu hút sự tham gia của các trường đại học, phòng thí nghiệm, viện nghiên cứu trên thế giới, với mục tiêu tạo dựng kho cơ sở kiến thức mở gồm các mô hình trí tuệ nhân tạo tối ưu nhằm chia sẻ cho cộng đồng công nghệ.
Wikipedia – Nguồn tài nguyên tuyệt vời chưa được tối ưu
Wikipedia chứa một số lượng lớn bài viết, và là một nguồn tài nguyên kiến thức tuyệt vời cho các tác vụ NLP (xử lý ngôn ngữ tự nhiên). Để sử dụng một cách tối ưu các kiến thức này, tài nguyên tạo được từ Wikipedia phải được cấu trúc theo quy luật, lý luận, và theo nhiều mục đích khác trong các ứng dụng NLP. Trong khi đó, những hệ kiến thức có cấu trúc hiện tại như DBpedia, Wikidata, Freebase, YAGO, và Wikidata, lại chủ yếu được tạo thông qua hình thức crowdsourcing (đóng góp cộng đồng), dẫn tới độ nhiễu cao trong các kệ kiến thức.
Để cấu trúc kiến thức chính xác hơn và có giá trị hơn, chúng phải được xây dựng từ trên xuống. Tức là thay vì sử dụng các lĩnh vực phân loại rườm rà sẵn có trên Wikipedia, ta cần phân loại kiến thức thành các lĩnh vực cụ thể, dễ xác định hơn. Trong số nhiều định nghĩa về lĩnh vực cụ thể, ENEs là một bản thể luận có tên riêng dễ xác định, bao gồm 200 lĩnh vực được phân theo bậc, với các đặc điểm riêng được định nghĩa cho từng lĩnh vực.
SHINRA là một dự án tạo tài nguyên được tổ chức lần đầu vào năm 2017 với mục tiêu hệ thống lại kiến thức trên Wikipedia. SHINRA2020-ML được tổ chức với tác vụ phân loại văn bản đầu tiên thuộc dự án SHINRA, tập trung vào việc phân loại kiến thức trên Wikipedia trong 30 ngôn ngữ thành nhiều lĩnh vực cụ thể.
Mục tiêu của dự án không chỉ dừng ở việc so sánh các hệ thống được sử dụng và chọn lọc ra các hệ thống có hiệu quả cao nhất, mà còn để tạo hệ kiến thức dựa trên đầu ra của các hệ thống này. Các công nghệ “ensemble learning” tiên tiến nhất có thể được sử dụng để lọc kết quả của các hệ thống, và tạo ra hệ kiến thức với độ chính xác cao nhất có thể.
Bài toán của SHINRA
Mục tiêu cuối cùng của SHINRA là tái cấu trúc các kiến thức trên Wikipedia theo các đặc điểm của chúng. Tuy nhiên, trước hết, cần phải phân loại mỗi trang Wikipedia về một lĩnh vực ENEs (Extended Named Entity). SHINRA2020-ML là tác vụ phân loại các trang Wikipedia trong 30 thứ tiếng thành các lĩnh vực ENEs (ver 8.0). Hiện nay, các trang Wikipedia Tiếng Nhật (920.000 trang) đã được hoàn tất trong việc phân loại, và có thể sử dụng các đường dẫn ngôn ngữ trên các trang này để tạo dữ liệu huấn luyện cho 30 ngôn ngữ khác. Do đó, tác vụ cần làm sẽ là phân loại các trang còn lại của những ngôn ngữ này theo dữ liệu huấn luyện.
Cụ thể, bài toán được đưa ra tại SHINRA2020-ML là phân loại kiến thức trên Wikipedia trong 30 ngôn ngữ thành 219 lĩnh vực được định nghĩa trong ENEs. Ban tổ chức cung cấp dữ liệu huấn luyện cho 30 ngôn ngữ, được tạo từ 920.000 trang Wikipedia Tiếng Nhật đã phân loại, kèm với đó là đường link Wikipedia cho 30 thứ tiếng. Ví dụ: trong số 2.263.000 trang Wikipedia Tiếng Đức, có 275.000 trang được dẫn nguồn từ Wikipedia Tiếng Nhật – khiến cho dữ liệu huấn luyện Tiếng Đức bị nhiễu. Do đó, tác vụ cần làm sẽ là “phân loại 1.988.000 trang còn lại thành 219 lĩnh vực, dựa trên 275.000 trang đã được phân loại sẵn.” Theo thống kê dữ liệu, 29 ngôn ngữ còn lại cũng có bối cảnh tương tự.
Dữ liệu đích cho từng ngôn ngữ sẽ được cung cấp dưới dạng tổng hợp các trang Wikipedia. Người tham dự sẽ được yêu cầu nộp đầu ra cho toàn bộ dữ liệu đích. Các dữ liệu submit sẽ được công khai, cho phép mọi người đều có thể thử nghiệm ensemble learning (sử dụng đồng thời nhiều mô hình máy học) để tạo tài nguyên cho các lĩnh vực Wikipedia trong 30 thứ tiếng.
30 ngôn ngữ mục tiêu được đưa ra trong cuộc thi: Tiếng Anh, Tây Ban Nha, Pháp, Đức, Trung, Nga, Bồ Đào Nha, Ý, Ả-rập, Indonesia, Thổ Nhĩ Kỳ, Hà Lan, Ba Lan, Ba-tư, Thụy Điển, Việt, Hàn, Hebrew, Romania, Na-uy, Séc, Ukraine, Hindu, Phần Lan, Hungary, Đan Mạch, Thái, Hi Lạp, Bulgary.
FPT.AI và mô hình đa ngôn ngữ hiện đại đầy hứa hẹn
Bài toán của SHINRA đưa ra trong cuộc thi yêu cầu phải xử lí một lượng dữ liệu rất lớn và hỗn độn; dữ liệu unbalanced sẽ dẫn đến những hạn chế trong việc ước lượng; bài toán yêu cầu xử lí multi-labels; mất nhiều thời gian training.
Để giải quyết những yêu cầu và khó khăn này, FPT.AI đã sử dụng mô hình BERT kết hợp với hierarchical multi-label classification để tạo ra một mô hình đa ngôn ngữ hiện đại. Cụ thể model gồm 2 phần: encoder và decoder. Tầng encoder sử dụng Multilingual bert base cased – một dạng Pretrained-model; decoder sử dụng mạng hierarchical multi-label classification để giải bài toán multi-label classification, với output có nhiều nhãn.
Trong cuộc thi, model của FPT.AI được training thành 3 giai đoạn:
- Giai đoạn 1: Tạo model cho tất cả các ngôn ngữ. Tuy nhiên, độ chính xác chạy trên tập dữ liệu chưa được cao.
- Giai đoạn 2: Fintuning cho từng ngôn ngữ mục tiêu. Model được tạo ra ở giai đoạn này được tối ưu cho một ngôn ngữ nên kết quả cao hơn model đầu tiên.
- Giai đoạn 3: Chiến thuật voting, sử dụng kết quả của các ngôn ngữ. Model này được tạo ra bằng cách tổng hợp kết quả prediction của các ngôn ngữ trên cùng 1 input, sau đó xác định kết quả cuối cùng dựa trên tần suất xuất hiện của các nhãn và sự phổ biến của ngôn ngữ.
Với việc thành công tạo ra model ở giai đoạn 3, model của FPT.AI đã vượt qua các đối thủ sừng sỏ và đạt kết quả Rank #1 ở 25/30 ngôn ngữ. Trong đó phải kể đến Studio Ousia – Công ty công nghệ nổi tiếng Nhật Bản vừa công bố mô hình NLP có tên “LUKE” – đứng vị trí đầu tiên trong SQuAD v1.1 leaderboard, với điểm số cao hơn cả những model như BERT (được phát triển bởi Google vào năm 2018), hay SpanBERT (được phát triển bởi Facebook vào năm 2019).
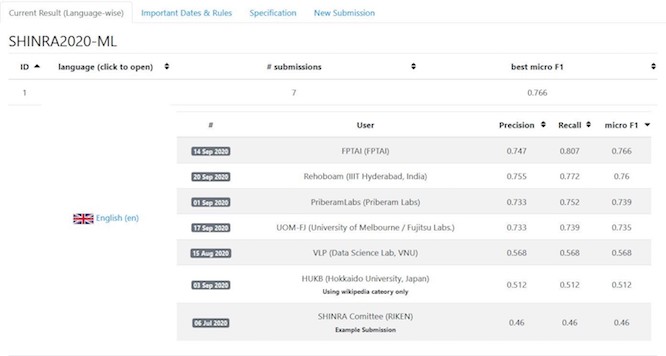
Thành tích xếp hạng của FPT.AI ở ngôn ngữ tiếng Anh.
Kết quả này là minh chứng cho năng lực công nghệ của FPT.AI không chỉ có sức cạnh tranh tại Việt Nam mà còn có thể bước ra khu vực và thế giới. Hiện, mô hình này đang được ứng dụng trong chatbot của FPT.AI để cải tiến mô hình truyền thống vốn gặp nhiều vấn đề về tốc độ xử lí và độ chính xác. Với việc ứng dụng giải pháp mới này sẽ giúp cải thiện khả năng tùy biến, chất lượng của chatbot, khắc phục những vấn đề mà mô hình truyền thống gặp phải.
Và với tiền đề vững chắc này, trong tương lai, FPT.AI sẽ nghiên cứu và phát triển để mở rộng chatbot sang các ngôn ngữ khác, từng bước chinh phục các thị trường khó như Nhật Bản, Hàn Quốc, Indonesia…
Thảo Nguyên – VietBT